结论
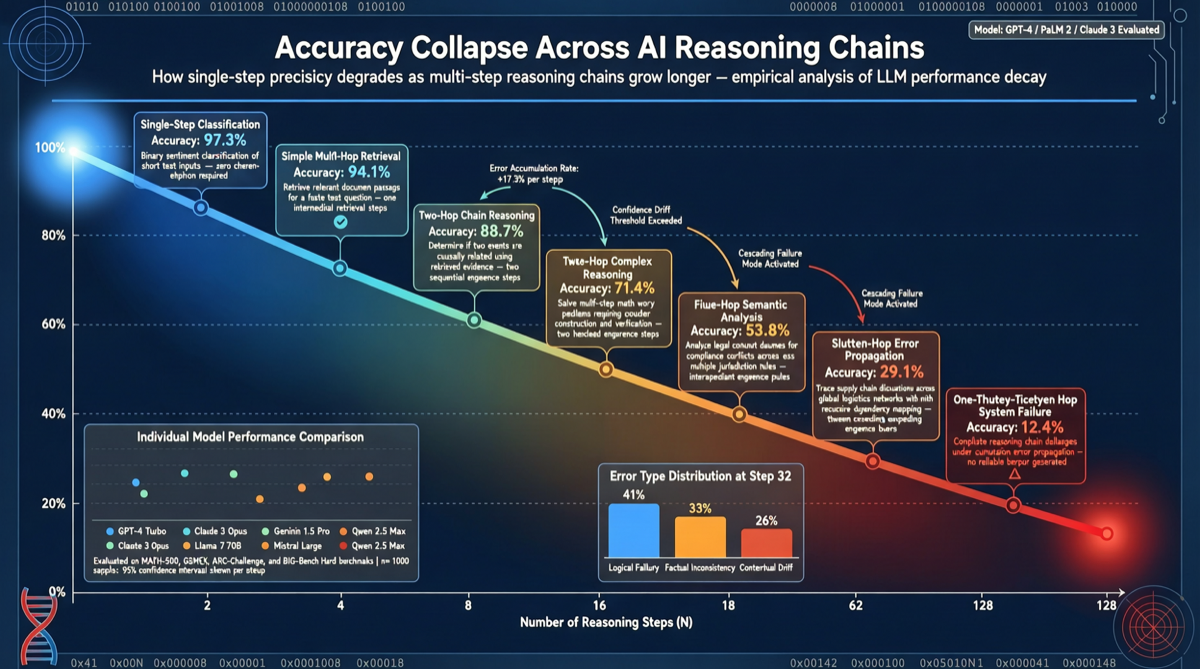
牛津大学与劳伦斯利弗莫尔国家实验室(LLNL)联合发布了一项关于长链条推理能力的基准研究。研究使用 GPT 5.2 作为测试对象,发现在单项问题上模型解决率高达 95.7%,但将相同问题串联为多步骤任务后,准确率暴跌至 9.83%。
这一结果揭示了当前 AI 模型的核心瓶颈:单体能力强大,但多步骤串联时误差累积导致系统级失败。研究团队指出,这不是一个能通过简单优化修复的问题。
测试维度
基准设计
研究团队选取了一组 GPT 5.2 能以 95.7% 准确率独立解决的问题。随后,他们将这些问题组织成一个需要按顺序完成的链条——每个步骤的输出作为下一步的输入。
结果:当这些高准确率的单项任务被串联后,整体准确率降至 9.83%。这意味着原本几乎完美的能力,在多步骤场景下几乎完全失效。
误差累积效应
准确率从 95.7% 到 9.83% 的暴跌,根源在于误差的级联放大:
- 第一步即使只有 4.3% 的失误率,也会污染后续所有步骤的输入
- 随着链条增长,复合错误率以指数级上升
- 模型无法在中间步骤”自查”和”纠错”
为什么”无法修复”
研究团队提出了三个核心原因:
- 自注意力机制的局限:Transformer 架构在处理长链条时,早期步骤的信息会被后续步骤的注意力权重稀释
- 缺乏中间验证:模型不会在每一步完成后主动验证输出正确性,而是直接传递给下一步
- 分布偏移:即使单步错误率很低,多步串联后的输入分布会迅速偏离训练数据分布
对实际应用的启示
| 场景 | 风险等级 | 说明 |
|---|---|---|
| 单次问答/分析 | 低 | 单项任务准确率仍然很高 |
| 多步骤工作流 | 高 | 链条越长,整体失败率越高 |
| 自主 Agent | 极高 | Agent 本质上是长链条推理,需要额外的错误恢复机制 |
| 科学发现流程 | 高 | 多阶段研究流程需要人工介入验证关键节点 |
选择建议
- 单次任务场景:当前模型足以胜任,95.7% 的准确率在多数场景下可接受
- 多步骤工作流:需要在关键节点加入人工审核或交叉验证,不能完全依赖模型自动串联
- Agent 开发:设计时必须包含错误检测和回退机制,不能假设链条能顺利执行到底
- 科研/工程决策:理解模型的”链式崩溃”特性,在关键流程中设置检查点