「ほとんどの人はAIを一つのツールだと思っている。」
そのツイートは先週65回閲覧された。バイラルじゃないけど、一つの真実を突いている:2026年のAIは層状のアーキテクチャになっており、各層が独立した購買決定、独立したコストセンター、独立した故障点になっている。
もしあなたがまだ「GPTにするかClaudeにするか」の思考で技術選定をしているなら、あなたのAIプロジェクトはすでに見えない層で技術的負債を蓄積しているかもしれない。
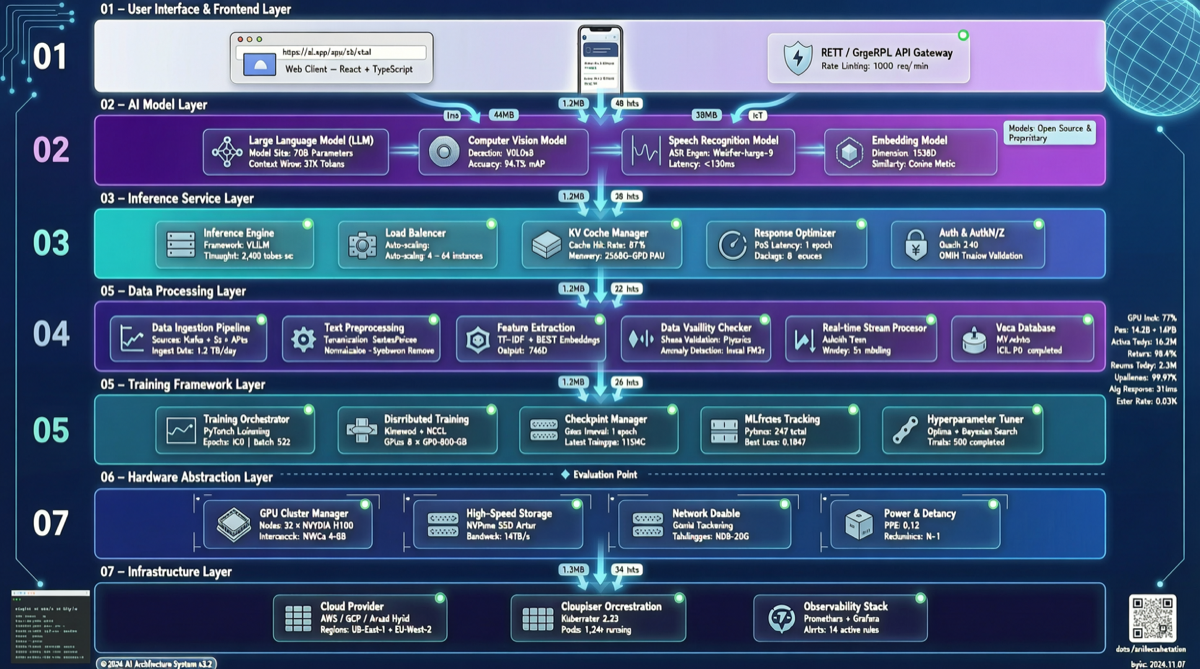
2026年のAIスタック
上から下まで、大体こんな感じだ:
第1層:ユーザーインターフェース。Webアプリ、CLI、IDEプラグイン、Slackボット、音声アシスタント。この層がユーザーとAIのインタラクション方法を決定する。
第2層:オーケストレーション。LangChain、OpenClaw、LangGraph、CrewAI。タスク分解、ルーティング、エラーリトライ、マルチエージェント調整を担当。
第3層:モデルルーティング層。どのリクエストがどのモデルに行くか決定。簡単な質問 → GPT-4o-mini、複雑な推論 → Claude Opus、コード → DeepSeek V4。良いルーティングでコストを40-60%に抑えられる。
第4層:基盤モデル層。GPT、Claude、Gemini、Qwen、DeepSeek、GLM。これが最も議論される層だが、実際には総コストの30-50%しか占めていない。
第5層:記憶とコンテキスト。ベクトルデータベース(Pinecone、Weaviate、Qdrant)、キャッシュ(Redis)、セッション管理。この層のコストは慢性的に過小評価されている。
第6層:ツールとデータ。MCPサーバー、APIコネクタ、データベースクエリインターフェース、ファイルシステム。エージェントが実際に「できるか」はこの層次第。
第7層:インフラ。GPUクラスター、推論サービス(vLLM、TGI)、ネットワーク、ストレージ。
七層。それぞれが進化し、それぞれがベンダーロックインのリスクを持っている。
最も見落とされている層
記憶層(第5層)。
ほとんどのチームは第4層(モデル選び)と第2層(オーケストレーションフレームワーク選び)に莫大な時間を費やすが、記憶層への投資は深刻に不足している。結果:AIは複雑な質問に答えられるが、ユーザーが前回何を言ったか覚えていない;または毎回会話ごとにナレッジベース全体を再ロードし、推論費用が急増する。
良い記憶アーキテクチャは三つのことをすべきだ:
- 短期記憶(セッション内コンテキスト)をモデルウィンドウ内に制御し、トークンの無駄を避ける
- 長期記憶(クロスセッション知識)はベクトル検索でオンデマンドにロードし、毎回プロンプトに詰め込まない
- 記憶の更新にバージョン管理を持たせる、そうでないと「AIが間違った情報を覚えてずっと間違え続ける」問題にぶつかる
ベンダーロックインが最も深刻な層
基盤モデル層。明らかだが、多くの人が気づいていない——プロンプトエンジニアリング、ツール呼び出しプロトコル、出力フォーマット解析がすべて一つのモデルに最適化されると、モデルを切り替えるコストは想像よりずっと高い。
より隠れたロックインはオーケストレーション層(第2層)にある。LangGraphで50のAgentワークフローを書いたら、別のオーケストレーションフレームワークに切り替えるには全部書き直す必要がある。这也是为什么一些チームが「軽量オーケストレーション+標準化プロトコル」を採用し始めている理由——重いフレームワークの代わりに単純なステートマシンを使い、移行コストを下げる。
一つの実践的アドバイス
AIプロダクトの構築を始めたばかりなら、または既存のAIワークフローをリファクタリングしているなら:
- モデルルーティング戦略を先に定義してから、モデルを選ぶ。逆ではない。
- 記憶層を一級市民として設計する、事後的なパッチではない。
- オーケストレーションを軽量に保つ。if-elseで解決できるルーティングに、重いフレームワークを使わない。
- 定期的にコスト監査を行う。毎月各層の費用占比を確認し、異常な成長ポイントを見つける。
AIスタックの各層は急速に変化している。今日のベストプラクティスは三ヶ月後には時代遅れかもしれない。しかし、このスタックの構造を理解することで、変化の中でも清醒を保てる。
主な情報源:
- X/Twitter コミュニティ議論("AI is a stack" スレッド、2026-05-10)
- 業界分析総合