«Большинство людей думают, что ИИ — это один инструмент.»
Этот твит получил 65 просмотров на прошлой неделе. Не виральный, но попал в точку: ИИ в 2026 году стал многослойной архитектурой, и каждый слой — это независимое решение о покупке, независимый центр затрат, независимая точка отказа.
Если вы всё ещё думаете о выборе технологий в терминах «GPT или Claude», ваш AI-проект, возможно, уже накапливает технический долг на слое, который вы не видите.
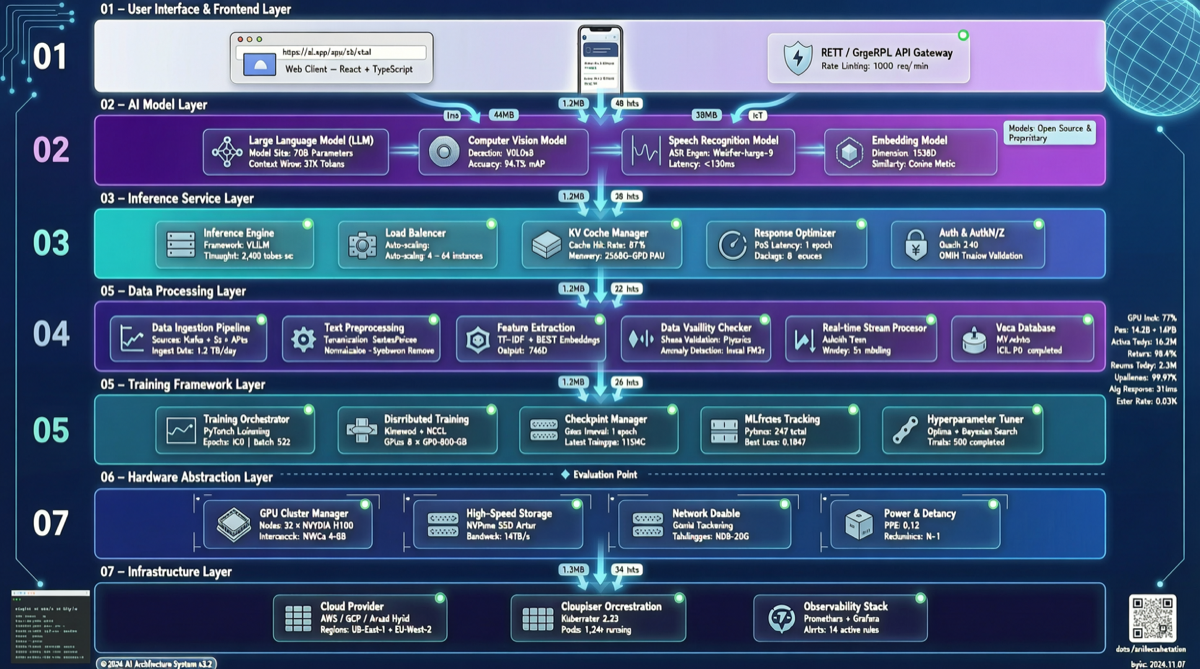
Стек ИИ 2026 года
Сверху вниз примерно так:
Слой 1: Пользовательский интерфейс. Веб-приложение, CLI, плагин IDE, Slack-бот, голосовой ассистент. Этот слой решает, как пользователи взаимодействуют с ИИ.
Слой 2: Оркестрация. LangChain, OpenClaw, LangGraph, CrewAI. Отвечает за декомпозицию задач, маршрутизацию, повтор при ошибках, координацию мульти-агентов.
Слой 3: Маршрутизация моделей. Решает, какой запрос идёт к какой модели. Простой вопрос → GPT-4o-mini, сложное рассуждение → Claude Opus, код → DeepSeek V4. Хорошая маршрутизация может снизить затраты до 40-60%.
Слой 4: Базовые модели. GPT, Claude, Gemini, Qwen, DeepSeek, GLM. Это слой, который все обсуждают, но на самом деле он составляет лишь 30-50% от общей стоимости.
Слой 5: Память и контекст. Векторные базы данных (Pinecone, Weaviate, Qdrant), кэширование (Redis), управление сессиями. Стоимость этого слоя хронически недооценивается.
Слой 6: Инструменты и данные. MCP-серверы, API-коннекторы, интерфейсы запросов к базам данных, файловая система. Могут ли агенты действительно «делать дела» — зависит от этого слоя.
Слой 7: Инфраструктура. GPU-кластеры, сервисы инференса (vLLM, TGI), сеть, хранилище.
Семь слоёв. Каждый эволюционирует, каждый с риском вендор-локина.
Самый игнорируемый слой
Память (Слой 5).
Большинство команд тратят огромное время на Слой 4 (выбор моделей) и Слой 2 (выбор фреймворков оркестрации), но серьёзно недоинвестируют в память. Результат: ИИ может отвечать на сложные вопросы, но не помнит, что пользователь сказал в прошлый раз; или перезагружает всю базу знаний для каждого разговора, стоимость инференса взлетает.
Хорошая архитектура памяти должна делать три вещи:
- Держать кратковременную память (контекст внутри сессии) в пределах окна модели, избегая потери токенов
- Использовать векторный поиск для долговременной памяти (межсессионные знания), загружая по требованию вместо того, чтобы запихивать всё в промпт
- Версионировать обновления памяти, иначе вы столкнётесь с проблемой «ИИ запомнил неправильную информацию и продолжает ошибаться вечно»
Где вендор-локин самый серьёзный
Слой базовых моделей. Очевидно, но многие не осознают — как только ваша промпт-инженерия, протоколы вызова инструментов и парсинг формата вывода оптимизированы под одну модель, стоимость переключения гораздо выше, чем вы думаете.
Более скрытый локин — в оркестрации (Слой 2). Если вы написали 50 Agent-воркфлоу в LangGraph, переход на другой фреймворк оркестрации означает переписывание всего. Именно поэтому некоторые команды начинают использовать «лёгкую оркестрацию + стандартизированные протоколы» — простые state machine вместо тяжёлых фреймворков для снижения стоимости миграции.
Одна практическая рекомендация
Если вы начинаете строить AI-продукт или рефакторите существующий AI-воркфлоу:
- Сначала определите стратегию маршрутизации моделей, потом выбирайте модели. Не наоборот.
- Проектируйте слой памяти как первоклассный компонент, не как заплатку после факта.
- Держите оркестрацию лёгкой. Если if-else решает вашу маршрутизацию, не используйте тяжёлый фреймворк.
- Проводите аудит затрат регулярно. Ежемесячная проверка процентного соотношения затрат каждого слоя, поиск аномальных точек роста.
Каждый слой AI-стека быстро меняется. Сегодняшняя лучшая практика через три месяца может быть устаревшей. Но понимание структуры стека помогает сохранять ясность в изменениях.
Источники:
- Обсуждения в X/Twitter (трэд "AI is a stack", 2026-05-10)
- Синтез отраслевого анализа