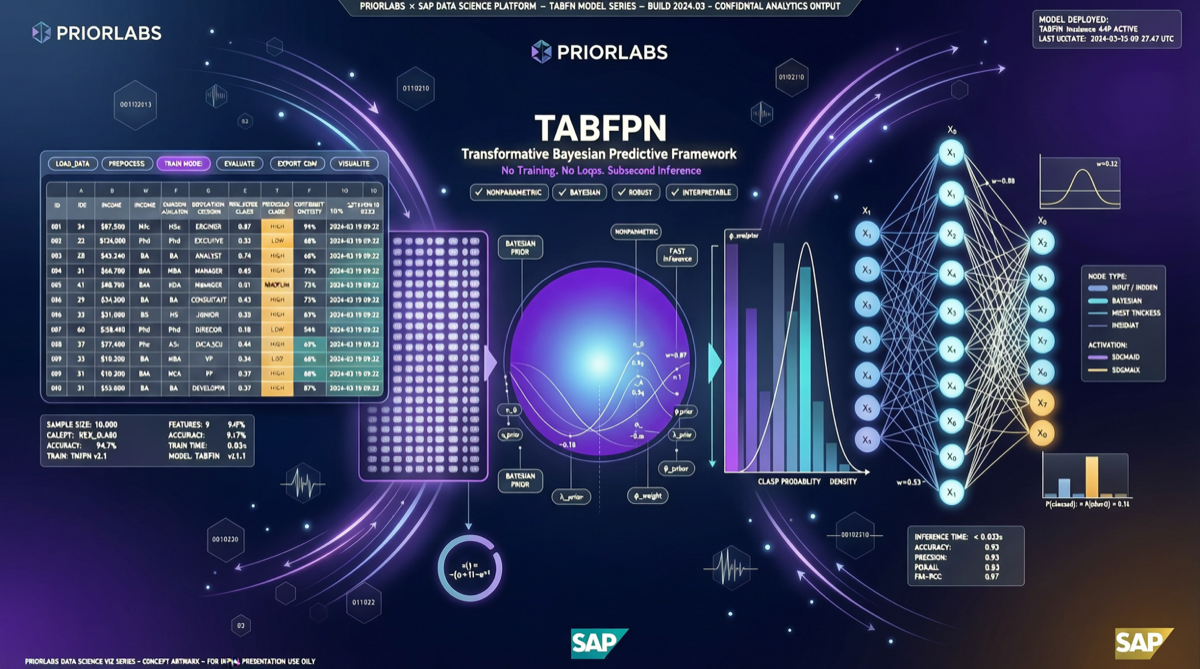
何が起きたのか
GitHub Trending で、PriorLabs/TabPFN が 6,650 の総スター数、日増 218 スターでトップポジションを維持し続けています。同時に、SAP は TabPFN の開発元 PriorLabs に対して 10 億ユーロ超の戦略的投資を発表しました——設立わずか18ヶ月のドイツAIスタートアップは、瞬時に欧州AI分野で最も注目されるプロジェクトの一つとなりました。
TabPFN が解決する課題
従来の機械学習は表格データ(tabular data)を処理する際、いくつかの頑固な問題に直面しています:
| 課題 | 従来のアプローチ | TabPFN のアプローチ |
|---|---|---|
| 小規模データセットの過学習 | 大量の特徴エンジニアリングが必要 | 事前学習済みTransformer、小規模データに自然適合 |
| モデル選択の難しさ | XGBoost、Random Forest、LightGBM の間で実験が必要 | 単一モデルが分類と回帰の両方を処理 |
| ハイパーパラメータチューニングに時間がかかる | グリッドサーチ / Optuna で数時間 | チューニング不要、开箱即用 |
| 推論速度 | アンサンブルモデルは遅い | 単一のフォワードパスで予測完了 |
**Prior-Data Fitted Network(PFN)**の核心アイデアはこうです:訓練フェーズで、モデルはデータセットから直接学習するのではなく、「大量の合成データセット上で良好なパフォーマンスを発揮する予測器」を学習します。つまり、新しいデータに遭遇したとき、TabPFN は再学習やチューニングを必要としません——「学習の仕方を学ぶ」プロセスを通じて表格データの普遍パターンをすでに習得しているのです。
なぜ SAP は 10 億ユーロを投資するのか
1. エンタープライズシナリオとの自然な適合
SAP のコアビジネスは ERP、CRM、サプライチェーン管理——これらすべてのシステムは毎日大量の表格データを生成しています。顧客分類、需要予測、異常検知、リスク評価……これらはすべて TabPFN の得意分野です。
2. LLM が苦手なこと、TabPFN が得意なこと
大規模言語モデルは自然言語の理解と生成で優れたパフォーマンスを発揮しますが、構造化表格データの予測タスク——特に小規模サンプルシナリオでは——専門の表格モデルに劣ることがよくあります。TabPFN は AI 能力マトリックスにおけるこのギャップを埋めます。
3. 欧州 AI の戦略的ポジショニング
欧州AI企業が一般的に資金調達の困難に直面する背景下で、SAP の巨額投資には強い戦略的意図があります:本土の AI 基礎モデル企業を育成し、次世代エンタープライズ AI インフラにおいて米国大手に完全に依存することを回避する。
技術比較
| 次元 | XGBoost | LightGBM | TabPFN |
|---|---|---|---|
| チューニングの必要性 | 必要 | 必要 | 不要 |
| 小規模データセット性能 | 普通 | 普通 | 優秀 |
| 大規模データセット性能 | 優秀 | 優秀 | 良好 |
| 推論速度 | 速い | 速い | 中程度 |
| 解釈可能性 | 中 | 中 | 低い |
| 使用のハードル | 中 | 中 | 低い |
使い方
クイックスタート:
from tabpfn import TabPFNClassifier
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5)
classifier = TabPFNClassifier()
classifier.fit(X_train, y_train) # チューニング不要
accuracy = classifier.score(X_test, y_test)
print(f"Accuracy: {accuracy}")
適用シナリオ:
- データサイエンス競技会のベースライン(多くの選手がすでにこれで好成績を収めている)
- 企業内部の小規模データセットでのクイックモデリング
- 複雑なチューニングロジックを維持したくない自動MLパイプライン
注意点:TabPFN は現在、行数が10,000以内のデータセットに最も適しています。超大規模データの場合、従来の勾配ブースティングツリーが依然としてより良い選択肢です。
格局判断
PriorLabs の 10 億ユーロの資金調達は、「垂直ドメイン基礎モデル」が AI 投資の新しいホットスポットになりつつあることを示しています。LLM(言語)、拡散モデル(画像)に続き、表格データ、時系列、グラフデータなどの垂直ドメインもそれぞれ独自の「基礎モデルモーメント」を迎える可能性があります。