发生了什么
Google 在 2026 年 5 月 1 日发布的 Gemini CLI v0.40.0 中引入了一个关键特性:实验性本地 Gemma 模型支持 + 智能路由架构。
这不是简单的”本地推理”功能,而是 Google 对 AI 工作流成本结构的一次重新设计。
智能路由架构
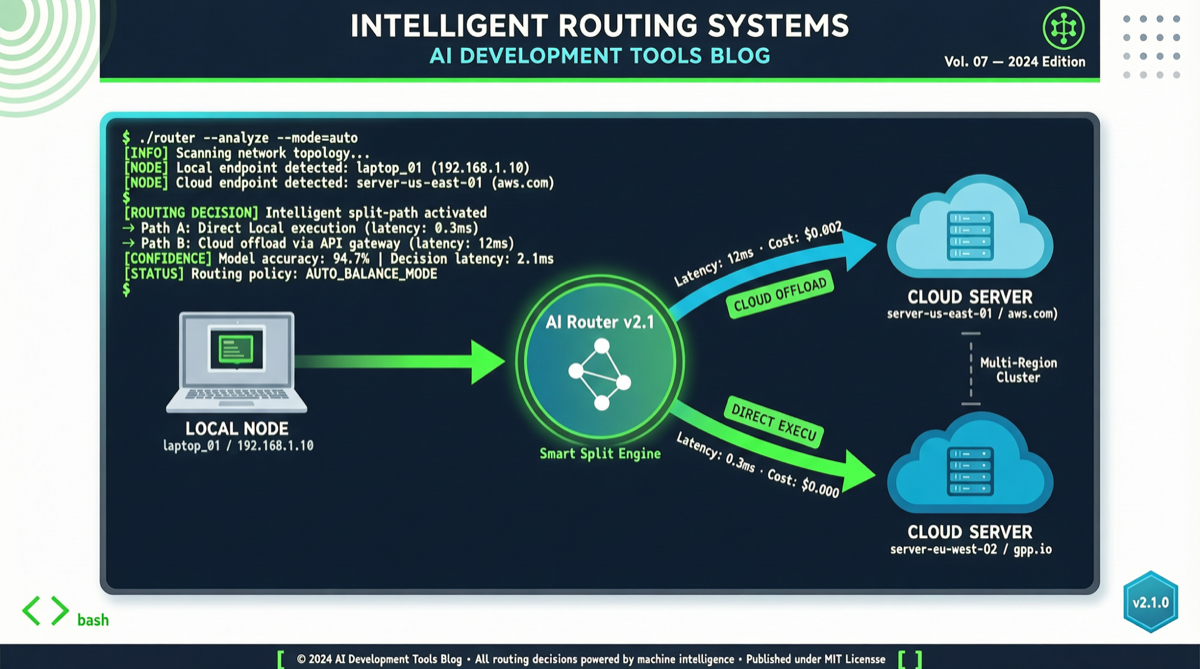
Gemini CLI v0.40.0 的核心创新在于”智能路由”机制:
你的请求 → CLI 判断复杂度
├── 简单任务(代码补全、文件搜索、格式整理)
│ → 本地 Gemma 模型(零 API 费用,<1s 响应)
│
└── 复杂任务(代码重构、架构设计、多步推理)
→ 云端 Gemini 模型(API 计费,完整推理能力)这意味着大多数日常开发任务可以在本地完成,只有真正需要强推理能力的场景才会触发云端 API 调用。
Gemma 4 26B A4B:消费级硬件的效率之选
与本地 Gemma 支持配套的,是 Gemma 4 26B 采用的 A4B(Activate 4 Billion)架构:
- 模型总量 26B 参数,但每个请求仅激活约 4B 参数
- 支持单台笔记本上多实例并发推理
- 可同时处理 10 个并发 prompt 而不出现性能瓶颈
- 完全本地运行,零 API 调用费用
这与 Qwen3.6 的策略形成鲜明对比:Qwen3.6 用更多 token 换更高分数,而 Gemma 走的是”够用就好”的轻量路线。
数据对比
| 维度 | Gemini CLI + 本地 Gemma | 纯云端 Gemini | Claude Code |
|---|---|---|---|
| 简单任务成本 | $0(本地运行) | 按 token 计费 | 按 token 计费 |
| 简单任务延迟 | <1s(本地) | 2-5s(网络往返) | 2-5s |
| 复杂任务成本 | 按 token 计费 | 按 token 计费 | 按 token 计费 |
| 复杂任务质量 | Gemini 云端模型 | Gemini 云端模型 | Claude 模型 |
| 隐私保护 | 简单数据不出本地 | 全部上传云端 | 全部上传云端 |
| 硬件要求 | 16GB+ RAM | 无 | 无 |
工作流成本优化实例
假设一个开发者每天使用 AI 编码助手的情况:
| 任务类型 | 日均次数 | 纯云端方案成本 | 智能路由方案成本 | 节省 |
|---|---|---|---|---|
| 代码补全 | 50 次 | $2.50 | $0 | $2.50 |
| 文件搜索 | 30 次 | $1.50 | $0 | $1.50 |
| Bug 分析 | 5 次 | $1.00 | $1.00 | $0 |
| 架构设计 | 2 次 | $2.00 | $2.00 | $0 |
| 日均总计 | 87 次 | $7.00 | $3.00 | $4.00/天 |
按月计算(22 个工作日),智能路由方案可节省约 $88/月。对于团队规模而言,这个数字会成倍放大。
上手步骤
# 1. 安装/更新 Gemini CLI 至 v0.40.0+
npm install -g @google/[email protected]
# 2. 下载本地 Gemma 模型
gemini-cli model download gemma-4-26b-a4b
# 3. 启动 CLI(智能路由默认开启)
gemini-cli
# 4. 验证本地模式是否生效
# CLI 会在处理简单任务时显示 [local:gemma] 标记路线图
v0.40.0 目前为”实验性”支持,Google 的完整路线图包括:
- 完全本地执行:未来版本将支持所有任务类型在本地完成(不依赖云端)
- 更多模型选择:除 Gemma 4 外,可能支持更多本地模型
- 企业部署:本地模型的企业级管理和安全策略
格局判断
Gemini CLI 的智能路由策略代表了 Google 对 AI 编码工具的独特定位:
- 不是纯本地工具(如 Continue + 本地模型),因为云端 Gemini 在复杂任务上仍有不可替代的优势
- 不是纯云端工具(如 Claude Code),因为大量简单任务不值得为 API 调用付费
- 混合路线:让工具自动判断”什么时候该花什么时候该省”
这对 Anthropic 和 OpenAI 的编码工具形成了差异化竞争——如果 Gemini CLI 的智能路由能准确区分任务复杂度,它将在成本敏感型开发团队中占据优势。
行动建议
- 个人开发者:如果你每月 API 费用超过 $50,强烈建议试用。安装门槛低,节省效果立竿见影
- 小团队(<10人):智能路由的成本优势在团队规模下会成倍放大
- 企业用户:等待”完全本地执行”版本,届时数据不出本地的合规优势将进一步放大