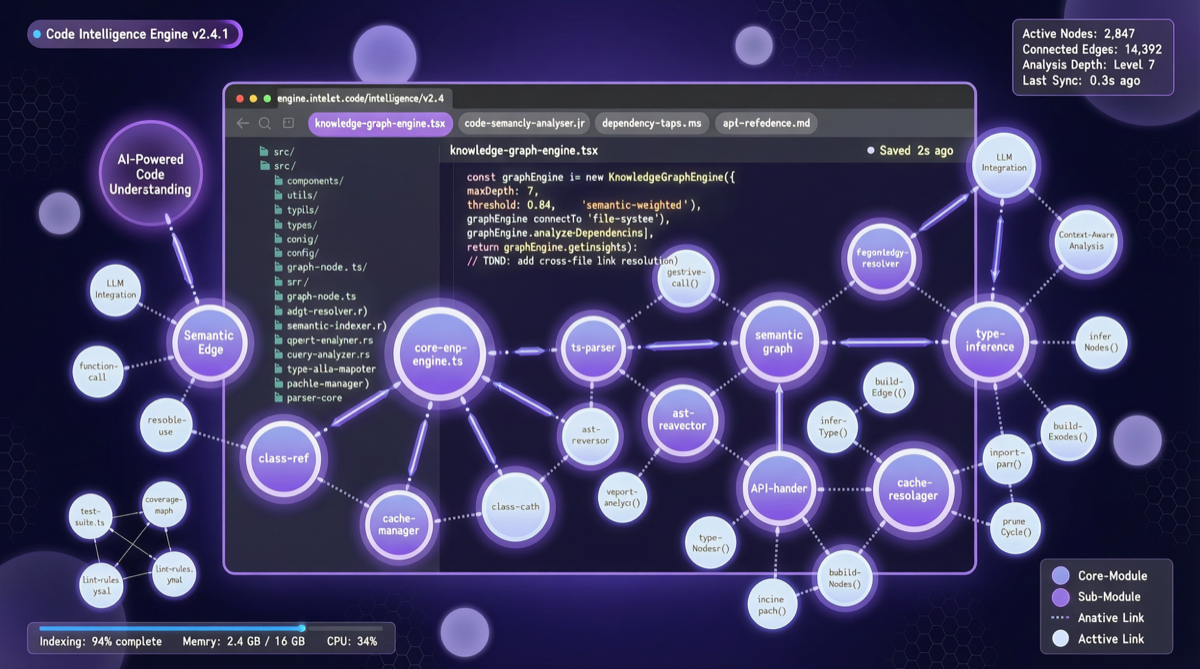
Bottom Line First
GitNexus is the fastest-growing code intelligence project on GitHub’s trending list this week — gaining 5,376 stars in a single week, surpassing 34,600 total. It addresses a long-ignored problem: when developers need to understand large codebases, traditional solutions either rely on expensive SaaS services or require building complex vector database + LLM pipelines. GitNexus’s answer: do everything in the browser.
Core Architecture: The Browser as Server
GitNexus’s tech stack is refreshingly radical:
| Layer | Technical Approach | Traditional Alternative |
|---|---|---|
| Graph Construction | Client-side AST parsing to build knowledge graphs | Server-side indexing + vector database |
| Storage | IndexedDB local persistence | Elasticsearch/Pinecone |
| Inference | Graph RAG Agent calls LLM API from frontend | Backend RAG pipeline orchestration |
| Deployment | Zero server, purely static hosting | Docker/K8s clusters |
| Input Source | GitHub repo URL or ZIP | Git clone + CI build |
Developers only need to do two things:
- Drag in a GitHub repo URL or ZIP file
- Wait for the browser to generate an interactive knowledge graph
Why Graph RAG Works Here
Traditional RAG’s weakness in code understanding: code isn’t natural language, and simple text chunking + vector retrieval loses call relationships, dependency topology, and module hierarchies.
GitNexus compensates with a knowledge graph:
- Entities: functions, classes, variables, modules
- Relationships: calls, inherits, depends on, references
- Graph Traversal: retrieves context along relationship paths, not semantic similarity
With the built-in Graph RAG Agent, developers can ask natural language questions like “How does authentication flow work in this project?” and the system organizes answers along the call chain in the knowledge graph.
Competitive Comparison
| Dimension | GitNexus | Sourcegraph | Bloop | Sepul |
|---|---|---|---|---|
| Deployment Cost | Zero | Self-hosted/Cloud paid | Self-hosted/Cloud paid | Cloud paid |
| Data Privacy | Purely local | Server-side processing | Server-side processing | Server-side processing |
| Graph Support | ✅ Knowledge Graph | ❌ Full-text index | ❌ Semantic search | ❌ Semantic search |
| Offline Capability | ✅ Works offline | ❌ Requires internet | ❌ Requires internet | ❌ Requires internet |
| Large Repo Performance | ⚠️ Browser memory limited | ✅ Distributed processing | ✅ Backend processing | ✅ Cloud processing |
Use Cases
- Onboarding new developers: Use GitNexus on day one to quickly grasp the overall architecture instead of reading files one by one
- Security auditing: Trace data flow paths to identify propagation chains of sensitive data
- Technology evaluation: Drop a candidate library’s ZIP file and judge code quality and architecture within 10 minutes
- Teaching demos: Real-time display of open-source project internal structure in classrooms or streams
Limitations
GitNexus isn’t replacing Sourcegraph or Bloop. Its positioning is more like a “quick scanner” — suited for exploratory scenarios, not production environments requiring persistent team-collaborative indexing. Very large repos (>1M LOC) will hit browser memory limits, a ceiling dictated by the technical architecture.
But that’s precisely its advantage: it doesn’t try to be everything, instead optimizing for “quickly understanding an unfamiliar codebase” to the extreme. 34K stars of growth speed proves market demand for lightweight code understanding tools.