Bottom Line First
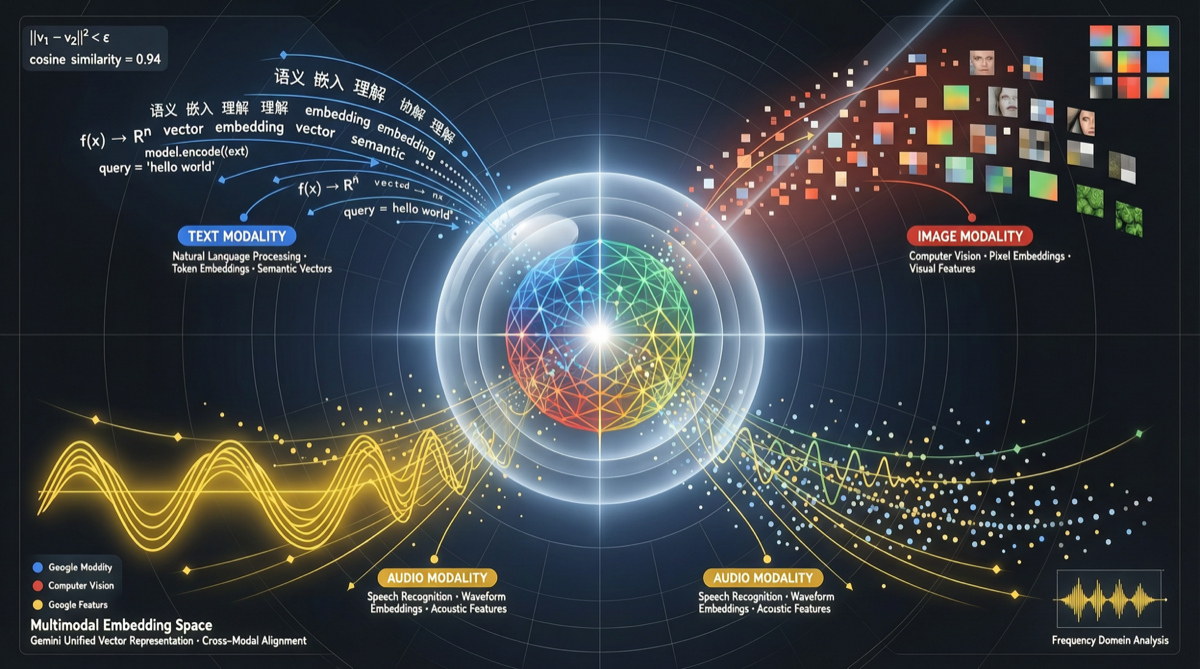
Google Gemini Embedding 2 solves a long-standing engineering pain point: different modalities require different embedding models, making it impossible for retrieval systems to do cross-modal semantic matching in a unified space.
Now text, images, and audio can be encoded into the same vector space — searching images with natural language, or searching for similar images, is achievable at the semantic level for the first time.
What Happened
Google AI officially announced Gemini Embedding 2:
- First fully multimodal embedding model: Built on Gemini architecture, not simple image+text stitching
- Unified vector space: Text, image, audio mapped to the same semantic space
- 100+ language support: Covers major languages, enabling cross-lingual semantic search
- API available: Preview access through Gemini API and Google Cloud Vertex AI
Technical Essence: Not Just “Stitching”
The key difference: this isn’t an engineering approach that simply concatenates image embeddings with text embeddings. Gemini Embedding 2 achieves at the model architecture level:
Text Input → [Gemini Encoder] → Unified Vector
Image Input → [Gemini Encoder] → Unified Vector
Audio Input → [Gemini Encoder] → Unified Vector
↑
Same encoding weightsThis means a natural language query (e.g., “a girl in a red dress running on the beach”) and a real photo have comparable semantic distance in the vector space — rather than searching in separate spaces and doing some kind of late fusion.
Application Scenarios
RAG Knowledge Base Upgrade
Traditional RAG limitations:
- Document retrieval only handles text
- Non-text content (images, tables, screenshots) requires separate processing
- Cross-modal retrieval (“find documents with architecture diagrams similar to this”) is nearly impossible
What Gemini Embedding 2 brings:
- Images in documents can be directly embedded into the same knowledge base
- Natural language queries can return both relevant text and relevant images
- Semantic integrity of multimodal documents is preserved
Semantic Leap for Image Search
Past image search:
- Based on visual feature similarity (color, texture, shape)
- “What does this image look like?”
Gemini Embedding 2 image search:
- Based on semantic understanding (image content, scene, relationships)
- “What does this image express?”
Comparison with Competitors
| Dimension | Gemini Embedding 2 | OpenAI text-embedding-3 | Cohere embed-v4 |
|---|---|---|---|
| Multimodal | ✅ Text + Image + Audio | ❌ Text only | ❌ Text only |
| Unified Vector Space | ✅ | N/A | N/A |
| Language Support | 100+ | 100+ | 100+ |
| Availability | Gemini API + Vertex AI | OpenAI API | Cohere API |
| Status | Preview | GA | GA |
Action Recommendations
| Your Scenario | Recommendation |
|---|---|
| Existing RAG system, need multimodal support | Connect Gemini Embedding 2 in test environment, compare with existing text-only retrieval |
| Image/video content platform | Rebuild content index with Gemini Embedding 2 for semantic-level recommendation and search |
| Cross-language document management | Leverage unified vector space to reduce translation layer cost and latency |
| Only need text embedding | Continue using mature text-embedding-3 for now; evaluate migration after Gemini Embedding 2 GA release |
Gemini Embedding 2 marks a key step for multimodal AI applications moving from “usable” to “good.” For projects handling mixed content types, this is a technology upgrade worth evaluating immediately.