Bottom Line First
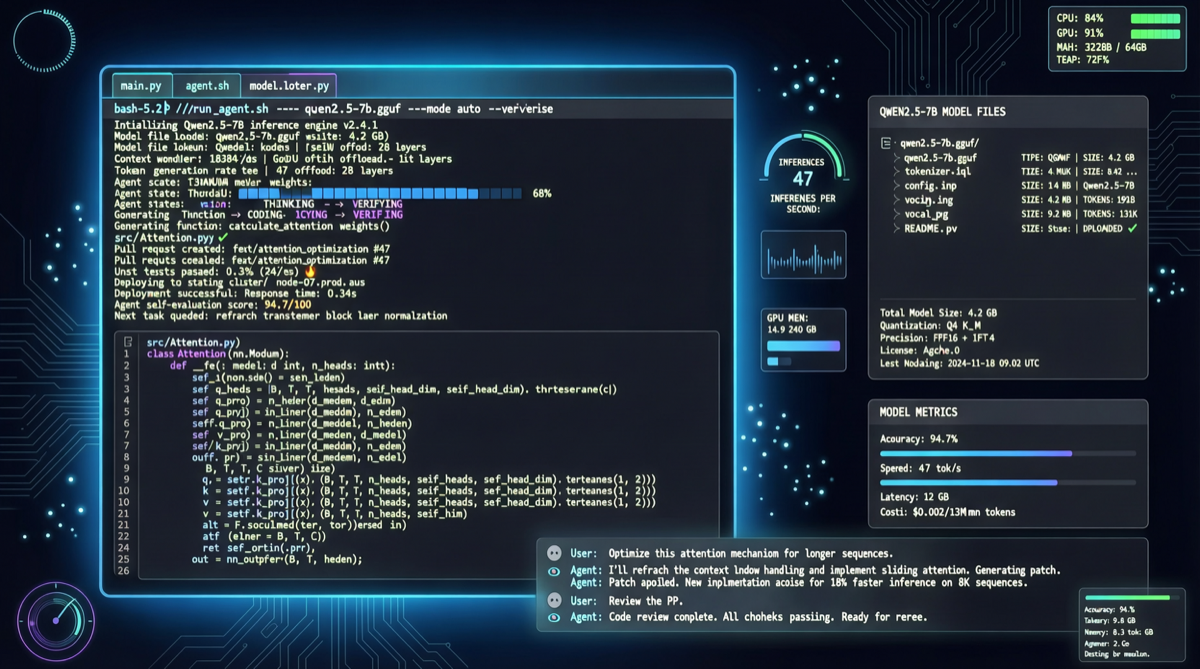
Unsloth just published a complete operational guide proving a counterintuitive conclusion: you don’t need Anthropic’s closed-source models, nor cloud GPU clusters. With just 24GB RAM + GGUF-quantized versions of Gemma 4 and Qwen3.6, you can run a full agentic coding workflow locally.
This means: code completion, file read/write, tool calling, and even self-healing retry after failures — all on a standard Mac or Linux laptop.
Core Data Comparison
| Dimension | Cloud Solution (Claude Code / Cursor Pro) | Unsloth Local Solution |
|---|---|---|
| Inference Model | Opus 4.5 / Sonnet 4 (closed-source) | Gemma 4-26B / Qwen3.6 (open-source) |
| Hardware Required | None (pay-per-use) | 24GB RAM + GGUF quantization |
| Cost Per Call | $0.015-$0.10/token | Electricity only |
| Data Privacy | Code uploaded to cloud | Fully local, zero transmission |
| Self-Healing Tool Calls | ✅ Supported | ✅ Supported |
| Offline Capable | ❌ | ✅ |
Technical Architecture Breakdown
GGUF Quantization Is the Key
The core of Unsloth’s approach is quantizing large models using the GGUF format. GGUF is the standard model format in the llama.cpp ecosystem, drastically compressing model size through Int4/Int8 quantization:
- Gemma 4-26B: ~16GB after quantization, suitable for medium-scale coding tasks
- Qwen3.6: ~14GB after quantization, better for Chinese code understanding
Both can run smoothly in a 24GB memory environment, and Unsloth’s real-world testing proves that quantized agentic capability shows almost no degradation.
Self-Healing Tool Calls
This is the key capability that makes local solutions competitive with cloud:
- Agent executes a tool call (read file, run test, search docs)
- If the tool returns an error or fails, the Agent automatically analyzes the error
- Adjusts parameters or strategy, retries the call
- Loops until success or max retry count is reached
This means the Agent is no longer a fragile “execute once and done” script, but a programming assistant with fault tolerance and adaptive capabilities.
Why This Matters
-
Cost structure completely changes: From “pay per token per call” to “deploy once, use infinitely.” For a developer using agentic coding daily to refactor code, monthly costs drop from $200+ to nearly zero.
-
Privacy compliance is essential: Many enterprise codebases cannot be uploaded to the cloud. Local solutions directly address this compliance pain point, especially critical for developers in finance, healthcare, and government sectors.
-
Qwen3.6’s Chinese advantage: The Qwen series has richer training data for domestic coding scenarios, showing significantly better understanding of Chinese comments, Chinese variable names, and domestic frameworks (Vue, WeChat Mini Programs, etc.) compared to overseas models.
Implementation Recommendations
Scenarios suited for local solutions:
- Daily code completion, refactoring, unit test generation
- Codebase exploration and understanding (requires reading large numbers of files repeatedly)
- Projects with strict data privacy requirements
Scenarios still requiring cloud:
- Complex architecture design needing SOTA reasoning
- Ultra-long context (1M+ tokens) full-repo analysis
- Scenarios needing the latest model capabilities (closed-source models iterate faster)
Quick Start
# 1. Install llama.cpp
brew install llama.cpp # macOS
# or build from source
# 2. Download GGUF model (Qwen3.6 example)
huggingface-cli download Unsloth/Qwen3.6-GGUF --include "*.gguf"
# 3. Start local server
llama-server -m qwen3.6-q4_k_m.gguf --port 8080
# 4. Configure local endpoint in Claude Code or OpenClaw
# Point to http://localhost:8080 and you're doneUnsloth’s complete guide includes detailed configuration files, performance tuning parameters, and common troubleshooting. Refer to the original tweet for the link.