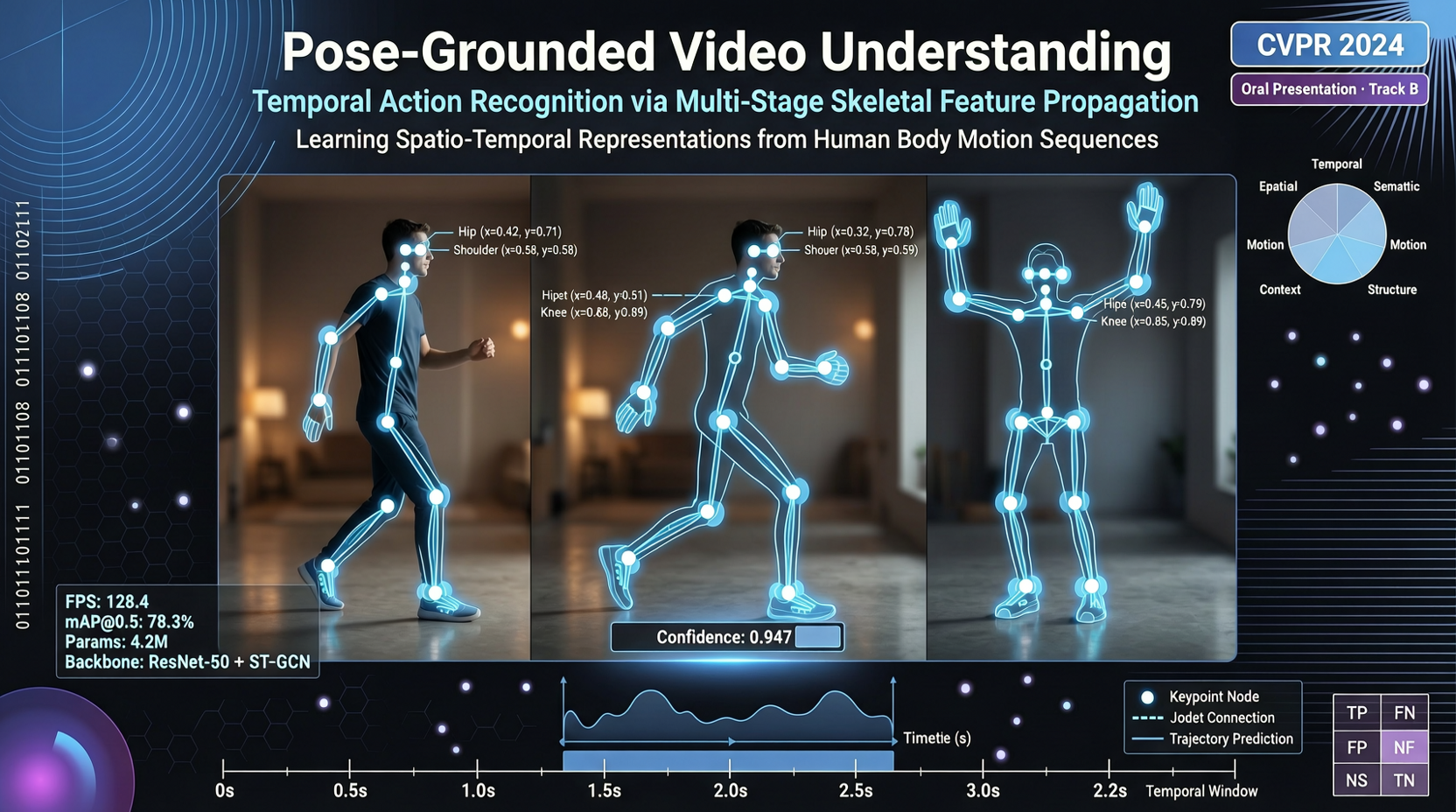
За последние несколько лет модели понимания видео значительно продвинулись, но одна проблема так и осталась нерешённой: в чём именно разница между тем, как модель воспринимает видео и стопку фотографий?
По своей сути большинство моделей понимания видео по-прежнему обрабатывают его как «последовательность изображений». Временное измерение добавлено, но недостаточно глубоко. Движения человека, изменения позы, траектории перемещения — эта уникальная для видео информация сплющивается до межкадровых различий, теряя при этом значительную часть структурированной семантики движения.
Исследовательская группа из NYU и других учреждений 21 мая представила статью Cambrian-P, в которой информация о позе (pose) напрямую вводится в модель понимания видео как объект первого класса. Данная работа уже принята на конференцию CVPR 2026.
Поза — не дополнительная функция, а ключ к пониманию видео
Основной тезис Cambrian-P предельно прост: изменения позы человека в видео являются самым прямым индикатором для понимания намерений действий, взаимодействий и семантики сцены.
Когда вы смотрите видео и понимаете, что «один человек учит другого боксу», это происходит не благодаря особой чёткости каждого кадра, а потому что вы улавливаете взаимосвязь изменений их поз: один показывает приём, другой повторяет. Подобное понимание крайне сложно построить, опираясь исключительно на визуальные признаки уровня отдельных кадров.
Cambrian-P объединяет оценку позы и понимание видео в единую архитектуру. Это не конвейерное решение по схеме «сначала запускаем модель оценки позы, а затем передаём её результаты в видео-модель», а совместное обучение в рамках одной модели.
Почему именно сейчас
Сама по себе оценка позы уже достигла высокой зрелости. Такие инструменты, как OpenPose и MMPose, обеспечивают точность вплоть до уровня суставов. Однако до сих пор не существовало проверенной парадигмы эффективной интеграции информации о позе в крупные модели понимания видео.
С одной стороны, согласование информации о позе и визуальных признаков нельзя решить простым объединением. С другой стороны, сами данные о позе зашумлены: перекрытия объектов, быстрые движения и слабое освещение приводят к неточным оценкам. Модель должна научиться возвращаться к чисто визуальному режиму, когда данные о позе ненадёжны.
Cambrian-P пытается ответить на вопрос: на каком именно уровне модели должна вмешиваться информация о позе? В качестве дополнительного входного канала, ограничения для промежуточных представлений или части обучающего сигнала?
Ограниченные детали статьи
На данный момент статья только что подана, поэтому подробное описание методов и экспериментальные результаты станут доступны после публикации PDF. На странице проекта (https://cambrian-mllm.github.io/) ожидается появление дополнительных визуализаций.
Тем не менее, если направление pose-grounded video understanding подтвердит свою эффективность на масштабных наборах данных, это окажет прямое влияние на ряд приложений: модерацию видеоконтента, спортивный анализ, человеко-машинное взаимодействие и даже прогнозирование поведения пешеходов в автономном вождении.
На что стоит обратить внимание
Среди авторов статьи значатся Saining Xie (NYU) и Bingyi Kang — оба имеют солидный бэкграунд в области компьютерного зрения и робототехники. Это не команда, которая «гонится за хайпом, публикует одну статью и исчезает», поэтому за их последующими работами определённо стоит следить.
Основные источники:
- Статья Cambrian-P (arXiv:2605.22819, 21 мая 2026 г.)
- Принято на CVPR 2026
- Страница проекта: https://cambrian-mllm.github.io/