Главное в двух словах
В сфере AI-инфраструктуры появилась четкая развилка: когда речь заходит о сверхдлинном контексте, индустрия раскалывается на два радикально разных технических подхода.
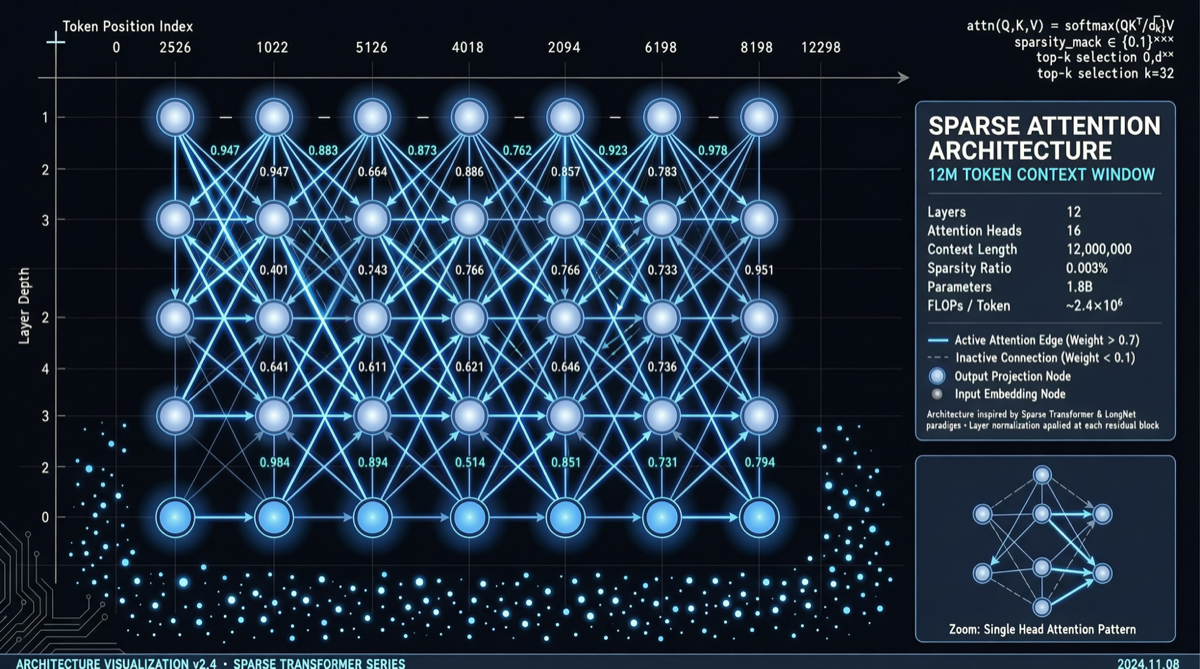
Подход первый (вертикальная интеграция): SubQ привлекла $29 млн на обучение модели с нуля, поддерживающей контекст в 12 миллионов токенов.
- Высокий риск, высокая отдача — в случае успеха и производительность, и эффективность контролируются
- Но требуются огромные вычислительные ресурсы и данные, и обслуживать можно только собственную модель
Подход второй (горизонтальное встраивание): MSA (Multi-Scale Attention) от evermind добавляет слой памяти поверх мейнстримных моделей.
- Работает с любой моделью, переобучение не требуется
- Но потолок производительности ограничен совместимостью механизма внимания хост-модели
Сообщество сформулировало точно: «Двадцать девять миллионов долларов на 12M контекст — это доказывает, что вся индустрия теперь верит: разреженное внимание — это лекарство от плотного внимания.»
Почему разреженное внимание?
Чтобы понять эту дискуссию, начнём с самой проблемы:
Традиционный механизм плотного внимания (dense attention) в Transformer сталкивается с двумя жёсткими ограничениями в сценариях длинного контекста:
- Вычислительная сложность O(n²) — удвоение контекста означает учетверение вычислений
- Взрыв памяти KV Cache — KV Cache на 12 млн токенов требует сотен гигабайт видеопамяти
Плотное внимание прекрасно работает до 128K, но за миллион токенов и стоимость, и задержка становятся неприемлемыми.
Ключевая идея разреженного внимания: не каждый токен важен для каждого другого токена. Избирательно вычисляя внимание, можно сохранить точность, снизив сложность практически до линейной.
Два подхода в деталях
SubQ: переобучить модель
SubQ выбрала самый агрессивный путь — обучить модель с нуля, которая нативно поддерживает контекст в 12 миллионов токенов.
- Преимущество: механизм внимания можно оптимизировать end-to-end для длинного контекста, обратная совместимость не нужна
- Недостаток: $29 млн в мире обучения моделей — это немного, маржа для ошибки крайне узкая
- Риск: если в процессе обучения обнаружится проблема с архитектурой, невозвратные затраты будут огромными
Что примечательно, API SubQ глубоко интегрирован с её продуктом — это подход «модель как сервис».
evermind MSA: добавить память к мейнстримным моделям
Multi-Scale Attention от evermind выбрала другой путь — не трогать веса модели, а подключить внешний слой памяти на этапе инференса.
- Преимущество: совместимо с Claude, GPT, Gemini и другими мейнстримными моделями — клиентам не нужно менять провайдера модели
- Недостаток: потолок производительности ограничен хост-моделью; по сути это решение-«заплатка»
- Риск: если мейнстримные модели сами добавят возможности длинного контекста, дифференциация MSA будет размыта
Сигналы от индустрии
Этот раунд финансирования раскрывает несколько примечательных сигналов:
- Разреженное внимание переходит из академической концепции в коммерческое русло — инвесторы готовы платить за «инновации в механизме внимания», а не просто за «более крупные модели»
- 12M контекст становится новым бенчмарком — до этого 1 миллион токенов (Claude) и 2 миллиона (Gemini) были публичным потолком; 12 миллионов — это скачок на порядок
- Ни один из подходов пока не победил — как в истории CNN против Transformer: раннее параллельное развитие нескольких направлений это здорово
Что это значит для разработчиков
| Сценарий использования | Рекомендуемый подход | Причина |
|---|---|---|
| Нужна экстремальная производительность длинного контекста | SubQ (если обучение удастся) | Нативное разреженное внимание, end-to-end оптимизация |
| Хочу существующие модели плюс длинную память | evermind MSA | Переключение модели не требуется, подключай и работай |
| Чувствителен к стоимости | Подождать | Оба подхода на ранней стадии, ценообразование пока непрозрачно |
Вывод
$29 млн — не гигантская сумма, но она знаменует сдвиг: конкурентная ось AI-инфраструктуры смещается вниз — от «у чьей модели больше параметров» к «у кого механизм внимания умнее».
Является ли разреженное внимание поистине окончательным лекарством от плотного внимания? Ответа пока нет, но этот раунд финансирования как минимум доказывает: нашлись те, кто готов ставить на это реальные деньги.