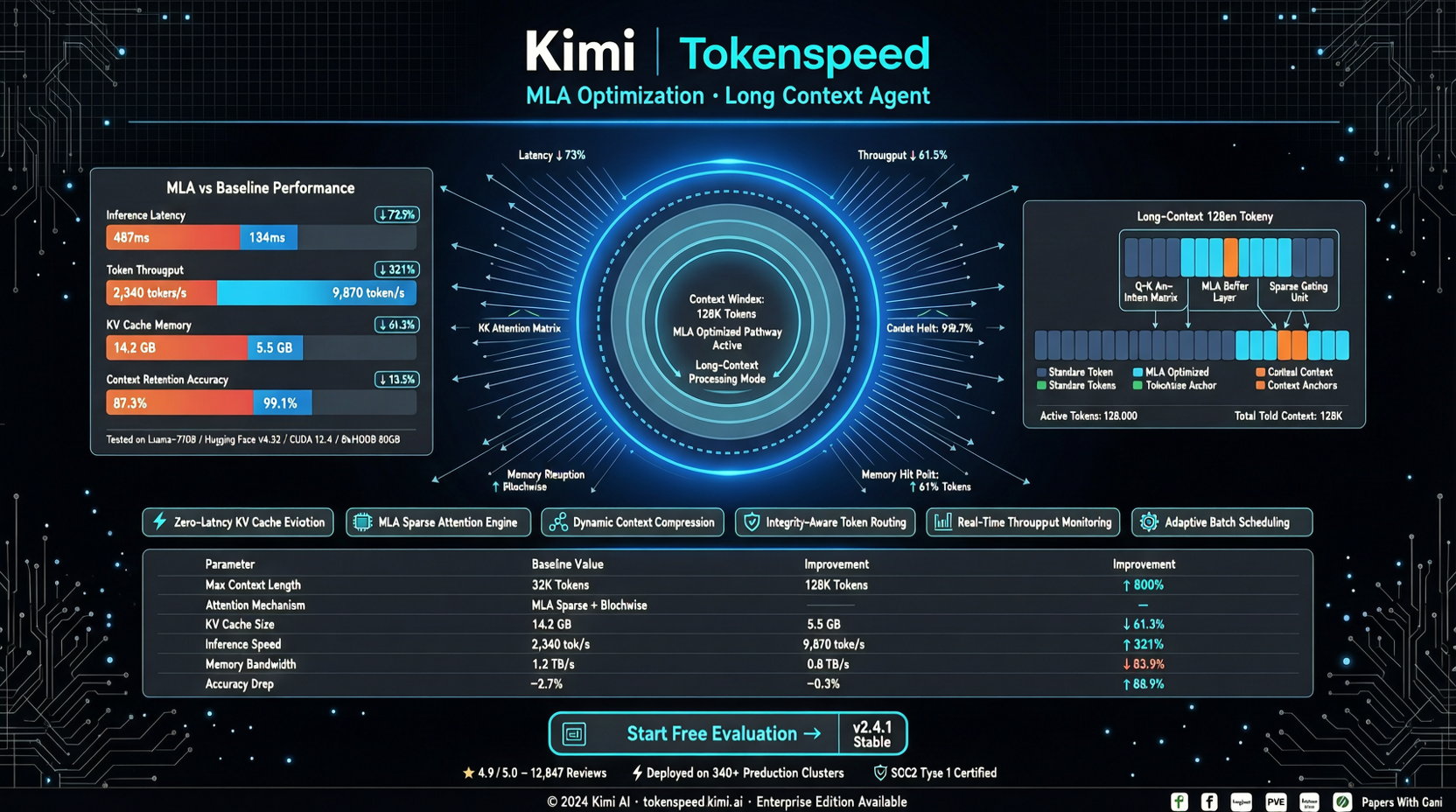
为什么 Agentic 场景需要专门的优化?
当前的 LLM 优化大多面向标准对话场景——用户问一句,模型答一句。但 Agent 工作负载完全不同:
- 长上下文持续累积:Agent 在执行任务时不断收集工具调用结果、中间状态和反馈,上下文窗口随时间持续增长
- 多轮推理密集:一个 Agent 任务可能触发 10-30 轮连续推理,每轮都需要完整的注意力计算
- 延迟敏感:Agent 的用户体验直接取决于每轮推理的延迟,累积延迟会导致整体体验崩溃
这就是为什么通用的 LLM 推理优化在 Agent 场景下效果有限——它们没有针对这些特殊模式做设计。
Tokenspeed MLA 库:专为 Agent 而生的优化
Tokenspeed 近日发布了其 MLA(Multi-Latent Attention)推理库的 day-0 版本,专门针对 Kimi 2.5/2.6 和 DeepSeek R1 在 NVIDIA 硬件上的 Agent 工作负载进行了优化。
核心优化方向:
1. 长上下文注意力压缩
MLA 架构本身就能显著降低长序列的注意力计算复杂度。Tokenspeed 在此基础上进一步优化了 KV cache 的管理策略,使得在 10 万+ token 的上下文下,推理延迟增长曲线更平缓。
2. 多轮对话的上下文复用
Agent 在多轮推理中,大量上下文是不变的(系统提示、工具定义、代码库索引)。Tokenspeed 的 MLA 库支持跨轮次的 context prefix 复用,避免重复计算。
3. NVIDIA 硬件深度适配
针对 Hopper(H100/H200)和 Blackwell(B100/B200)架构进行了 FP8 推理优化,同时也兼容 RTX 5090 等消费级显卡。
Kimi 2.5/2.6 在 Agent 赛道的定位
月之暗面的 Kimi 系列一直是中国 AI 在 Agent 赛道的重要参与者:
- Kimi K2.6:在 4 月发布的多模型横评中,Kimi K2.6 在中文 Agent 场景表现出色,尤其在多工具调用和长上下文理解方面
- Kimi 2.5/2.6 连续迭代:月之暗面保持了快速的迭代节奏,每代都在 Agent 能力上有所增强
Tokenspeed MLA 库的发布,为 Kimi 在 Agentic 场景下的部署提供了一个性能放大器——同样的模型,经过 MLA 优化后,在 Agent 工作负载下的吞吐量和延迟都会有可感知的改善。
对开发者的实际意义
如果你正在使用或考虑使用 Kimi 2.5/2.6 构建 Agent 应用,以下是关键信息:
部署层面:
- Tokenspeed MLA 库需要 NVIDIA GPU(Hopper/Blackwell 架构效果最佳)
- 与 DeepSeek R1 共享同一优化路径,如果你同时使用多个模型,可以复用同一套基础设施
性能预期:
- 长上下文(10 万+ token)场景下的推理延迟预计降低 30-50%
- 多轮 Agent 任务的端到端耗时预计降低 20-40%
- 显存利用率提升,同等硬件下可以处理更长的上下文
生态位置:
- Kimi 目前在国产模型中 Agent 能力排名第一梯队
- MLA 优化补齐了部署层面的性能短板
- 结合 Ollama 等本地部署工具,Kimi 的 Agent 能力可以延伸到更多场景
横向对比:Kimi vs 其他国产模型在 Agent 赛道的进展
| 模型 | Agent 能力亮点 | 部署优化进展 |
|---|---|---|
| Kimi 2.5/2.6 | 中文 Agent 场景领先,多工具调用成熟 | Tokenspeed MLA 库优化 |
| DeepSeek V4-Pro | 1M 上下文,开源权重 | Ollama 原生支持 |
| Qwen 3.6 | 消费级 GPU 可运行,轻量 Agent | 多种量化方案支持 |
| GLM-5.1 | SWE-bench 接近 Claude Opus 4.7 | 开源 Agent 策略 |
| MiniMax | Sentient Arena 评测表现亮眼 | 云端 API 为主 |
Kimi 的优势在于 Agent 场景的端到端体验——从模型能力到推理优化再到生态集成,正在形成完整的技术栈。
总结
Tokenspeed MLA 库的发布,是 Kimi 在 Agentic 赛道上的又一基础设施加持。对于正在评估国产模型用于 Agent 应用的开发者来说,这进一步缩小了国产模型与国际前沿在部署性能层面的差距。
Kimi + MLA 优化 + 丰富的 Agent 工具生态,这条技术路线正在变得越来越有说服力。