结论
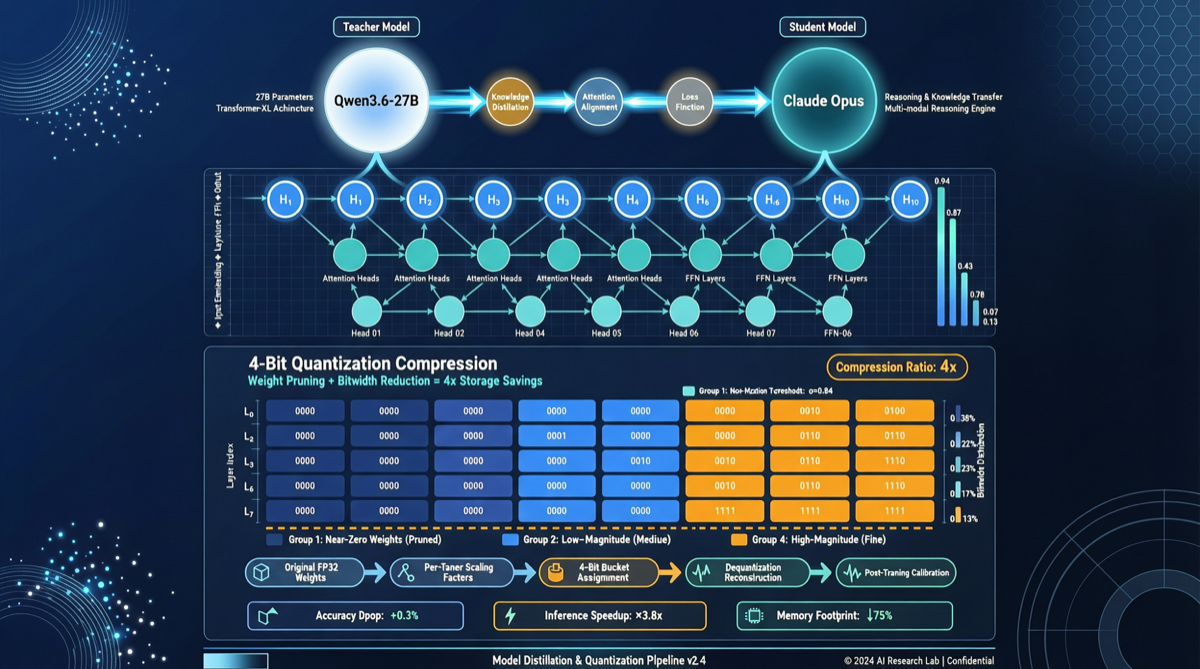
一个 270 亿参数的开源模型,正在把曾经只有闭源旗舰才能提供的推理能力,打包成 4-bit 量化版本塞进消费级 GPU——Qwen3.6-27B-Claude-Opus-Reasoning-Distill-v2-int4-AutoRound 的出现在 Hugging Face 社区引发了 4000+ 浏览、67 次收藏,背后传递的信号很明确:开源推理模型的门槛正在被大幅压低。
蒸馏到底蒸馏了什么
这个模型的核心思路不复杂但很有效:
- 基座:Qwen3.5(阿里通义千问系列的推理优化版),27B 参数量
- 蒸馏源:Claude Opus(Anthropic 旗舰模型)的推理轨迹(reasoning traces)
- 量化:AutoRound 框架的 int4 量化方案
蒸馏不是简单的”模仿输出”,而是学习 Opus 在复杂推理任务中的思考路径——如何拆解问题、如何逐步验证、如何在不确定时表达置信度。
具体来说,训练流程大概是这样的:
- 用 Claude Opus 生成大量高质量 reasoning 样本(数学推理、代码推理、逻辑链)
- 在 Qwen3.5 上训练,让它的 hidden states 对齐 Opus 的中间表示
- 用 AutoRound 做 4-bit 量化,压缩到可在 24GB 显存运行
为什么 27B + 4-bit 是关键数字
这个组合不是随意的。27B 参数量的模型在经过 4-bit 量化后,权重仅需约 13-14GB 显存,加上 KV cache,24GB 的消费级 GPU(RTX 3090/4090)就能完整加载并运行。
对比几个关键数字:
| 模型 | 参数量 | 量化后显存 | 推理能力对标 |
|---|---|---|---|
| Claude Opus 4 | ~数千B | 无法本地运行 | 旗舰级 |
| Qwen3.5-72B | 72B | 48GB+ (FP16) | 强推理 |
| Qwen3.6-27B-int4 | 27B | ~14GB | 接近 Opus |
这意味着:个人开发者第一次可以在本地跑一个接近 Opus 推理能力的模型。
社区反应
X/Twitter 上的帖文收获了 75 个 likes、67 个 bookmarks,在 AI 模型类帖文中属于高互动比。评论区的核心观点集中在:
- “This is advanced text and image reasoning compressed into a 4-bit quantized package” — 文字和图像推理能力被压缩进了 4-bit 量化包
- 关注点主要在消费级 GPU 可用性和推理质量与原始 Opus 的差距
- 部分用户已经在本地部署测试,反馈”在数学推理和代码生成任务上表现超出预期”
对国产模型生态的意义
Qwen 系列一直走的是”开源 + 强推理”路线。这次蒸馏版本的出现在几个维度上有标志性意义:
- 打破闭源推理能力垄断:Opus 级别的推理能力第一次以开源形式出现在 27B 量级
- 降低本地部署门槛:24GB 显存即可运行,覆盖了绝大多数个人开发者的硬件条件
- 蒸馏技术验证:证明了用闭源旗舰的输出训练开源小模型,是一个可行的能力跃升路径
你可以怎么用
- 本地推理测试:如果你有一张 24GB 显存的 GPU,直接下载模型试试效果。用 Ollama 或 vLLM 加载都可以
- Agent 框架集成:Hermes Agent、OpenClaw 等 Agent 框架支持自定义模型端点,可以把这个模型作为推理后端
- 对比评测:和 DeepSeek V4、GLM-5.1 等模型在相同任务上跑 benchmark,看看蒸馏效果是否如预期
风险与局限
蒸馏模型不是万能的:
- 知识截止:蒸馏模型的训练数据取决于 Opus 当时的知识窗口
- 领域偏移:在某些 Opus 不擅长的垂直领域,蒸馏效果可能打折
- 量化损失:4-bit 量化对复杂推理链的精度有一定影响,关键场景建议用 FP16 版本
一句话
Qwen3.6-27B 蒸馏版的出现,标志着开源推理模型正在从”能用”向”好用”跨越——而且这个”好用”已经跑进了消费级显卡的显存里。